Use image embeddings for finding similar images and clustering images
By using Deep Learning for images we can create so called ‘image embeddings’. An image embedding, is an image converted to a set of numbers (called a vector) using an AI model.
In this blog post, we’ll explore how to use image embeddings for similarity search and clustering, with a focus on OpenAI CLIP, cosine similarity, and KMeans clustering.
By doing this we can better handle large sets of image data. We can find similar images for an image and we can cluster images.
Understanding Image Embeddings
Before diving into similarity search and clustering, it’s essential to understand what image embeddings are. In simple terms, an image embedding is a numerical representation of an image in a high-dimensional space. These embeddings are generated by AI-models trained to capture the semantic content of images, meaning that similar images will have similar embeddings. In the image below you can see how this works.
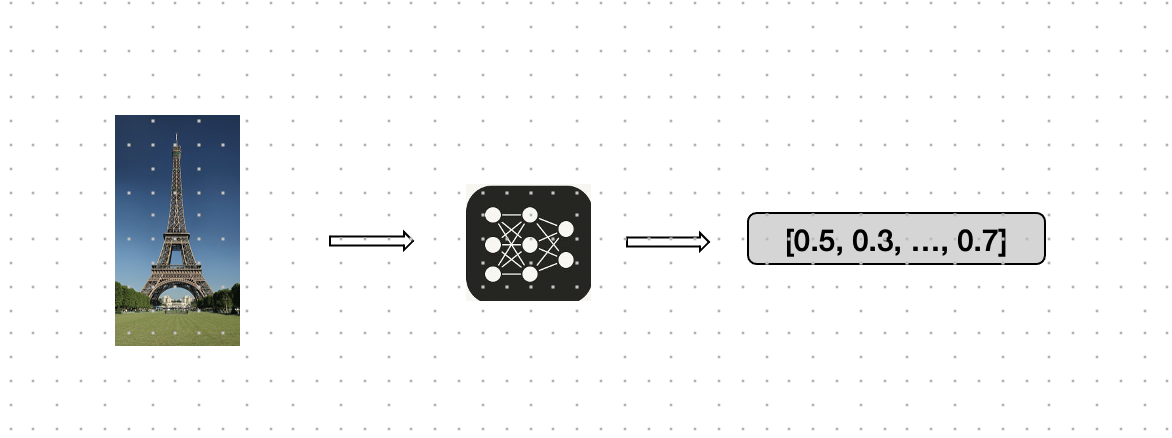
Image embeddings are typically generated using convolutional neural networks (CNNs) or transformer-based models like OpenAI’s CLIP. The advantage of using embeddings is that they condense complex image data into a compact, fixed-size vector that can be easily compared and processed.
OpenAI CLIP: Bridging Images and Text
OpenAI’s CLIP (Contrastive Language–Image Pre-training) is a groundbreaking model that can understand and relate images and text in a shared embedding space. CLIP was publhshed in 2020 and is trained on a vast dataset of image-text pairs. The model learns to relate visual objects (like apples or elephants) with corresponding textual descriptions. As a result, CLIP can generate embeddings for both images and text.
With CLIP, you can encode images into embeddings that capture not just the visual content but also the semantic meaning, making it incredibly effective for tasks that require understanding an image.
Cosine Similarity: Measuring Similarity Between Images
Once we have our image embeddings, the next step is to measure the similarity between them. Cosine similarity is a popular metric for this purpose. It calculates the cosine of the angle between two vectors (in this case, two image embeddings), providing a measure of how similar they are. The cosine similarity score ranges from -1 to 1, where:
1 indicates that the vectors are identical (i.e., the images are very similar), 0 indicates that the vectors are orthogonal (i.e., the images are unrelated),
Cosine similarity is particularly useful for high-dimensional data like image embeddings, where Euclidean distance might not be as meaningful.
Similarity Search with Image Embeddings
With image embeddings and cosine similarity, we can perform a similarity search, which involves finding images in a dataset that are similar to a given query image. The process is straightforward:
- Embed the Query Image: Use a model like CLIP to convert the query image into its embedding.
- Compute Similarities: Calculate the cosine similarity between the query image’s embedding and the embeddings of all images in the dataset.
- Rank and Retrieve: Sort the images based on their similarity scores and retrieve the top results.
This method allows you to search for visually and semantically similar images without relying on manual tags or keywords, making it highly scalable and accurate.
Clustering Images with KMeans
Clustering is another powerful application of image embeddings. By grouping similar images together, you can organize large datasets. One popular clustering algorithm is KMeans.
With the KMeans algorithm, you can create clusters of your images. In our example (see notebook below) it is able to correctly identify and cluster the images of fruits, faces and elephants.
Conclusion
We’ve seen that image embeddings, powered by models like OpenAI CLIP, are a solution for tasks like similarity search and clustering. By using these techniques, you can unlock new ways to explore, search, and organize image data.
Notebook
If you want to learn more and dive into the code, see the notebook below. With the notebook you can download a small image dataset with fruits, faces and elephants.
image similarity search and clustering notebook
This blogpost was created with help from ChatGPT. THanks to Ed Kuijpers for reviewing the notebook.